2025年07月08日
在档案管理领域,撰写一份高质量的全宗介绍往往需要档案专家花费数天甚至数周时间,从海量数据中梳理机构沿革、归纳档案内容、整理统计信息。如今,借助大语言模型( LLM )与智能数据流水线技术,这一繁琐任务可以在几分钟内完成 !本文将深入解析这套自动化方案的核心技术细节,带您了解AI如何赋能档案管理工作。
技术方案详解 :四层智能流水线
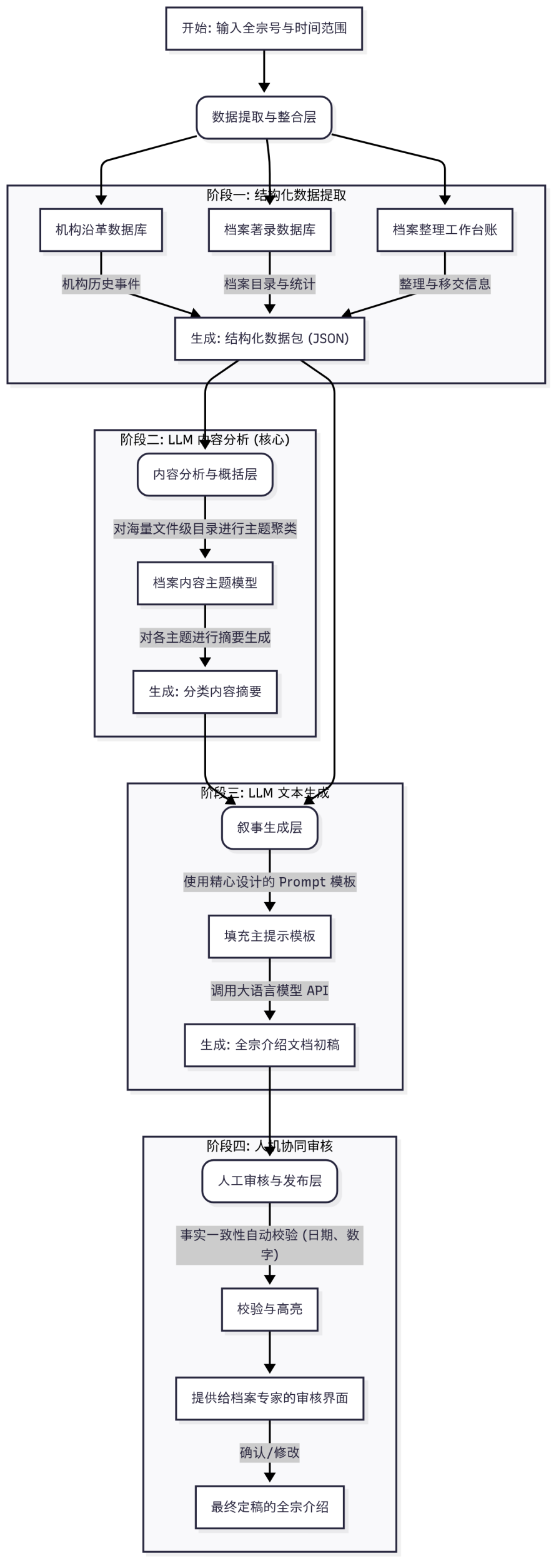
1. 数据提取与整合层——精准抓取多源异构数据
· 数据连接器 (Data Connectors ) :针对不同数据库开发定制化接口,例如:
。 机构沿革数据库 :通过API或SQL查询,提取机构设立、合并、撤销、领导任免等关键事件的时间线(精确到年月日)。
。 档案著录系统 :批量导出指定全宗号下的案卷/文件级目录,包括题名、关键词、摘要、文件类型等字段,并统计文件类 型分布(如“党群类占比30%”)。
。 整理工作台账 :获取整理人、整理时间、物理数量(卷/件数)、载体类型(纸质/电子)、排列方式等结构化数据。
· 数据标准化 :将所有数据整合为统一的JSON格式,例如:
2. 内容分析层——LLM驱动的智能聚类与摘要
· 主题聚类 (Topic Clustering ) :
。 输入 :上万条文件题名(如“1985年XX局党组会议记录”“1990年干部任免通知”)。
。 方法 :调用LLM(如GPT-4)进行语义聚类,预设种子类别(如“党群工作”“行政管理” ),同时允许模型发现新类别。
。 关键技术 :采用 嵌入向量 (Embedding ) 计算题名相似度,结合聚类算法(如K-Means )生成分类标签。
· 分类摘要 (Summarization ) :
。 Prompt示例 :
text 你是一名资深档案员。以下是‘行政管理类’的50条文件题名 :[ . . .]。请用一段话总结这类档案的核心内容 ,需体现时间范围、文件类型和主要职能。
。 输出 :生成高度概括的段落,例如:
> “行政管理类档案(1950–2000年)主要包括局务会议记录、年度工作计划、工作总结等,反映了XX局在政策制定、执 行监督方面的核心职能。 ”
3. 文本生成层——结构化数据转自然语言
· 主提示模板 (Master Prompt ) :
设计多角色指令模板,严格遵循档案学规范:
. 生成优化 :
。 温度参数 (Temperature) 设为0.3 ,减少随机性,确保表述严谨。
。 后处理 :自动校验数字一致性(如“500卷”是否与原始数据匹配)。
4. 人机协同层——审核与知识沉淀
. 自动校验 :
。 正则表达式提取生成文本中的日期、数量,与原始数据比对,标注差异(如“生成文本: 1980年;原始数据: 1981 年”)。
. 审核界面 :
。 前端采用Markdown实时渲染,右侧悬浮原始数据面板,支持专家点击修改并记录反馈(反馈数据用于迭代优化模型)。
技术优势 :为什么选择这一方案?
1. 语义理解能力 :LLM可识别“XX局第N次党组会议”与“XX局党委会议”属于同一主题,避免传统关键词匹配的局限。
2. 动态扩展性 :新增档案类型时,只需在Prompt中添加种子示例,无需重新训练模型。
3. 资源节约 :相比人工撰写,成本降低90%以上(实测生成一篇5000字全宗介绍仅需2分钟)。
未来方向 :从自动化到智能化
. 多模态支持 :未来可整合扫描件OCR文本,补充档案内容分析。
. 知识图谱构建 :将机构沿革与档案内容关联,生成可视化时间轴。
结语
这一方案不仅是技术的创新,更是档案管理理念的升级——让AI成为档案专家的“智能助手” ,释放人力专注于更高价值的学术研 究。如果您想体验技术Demo或获取完整技术方案,欢迎联系我们的技术团队!

公众号

视频号
Copyright © 2025. www.aesinfo.cn.All Rights Reserved.  沪公网安备 31010702007084号 沪ICP备2021003609号-7
沪公网安备 31010702007084号 沪ICP备2021003609号-7

渠道合作


联系电话:
400-720-0100




 400-720-0100
400-720-0100

